- 베이스텐·딥인프라·파이어웍스 AI·투게더 AI, 블랙웰 최적화 스택으로 효율 극대화

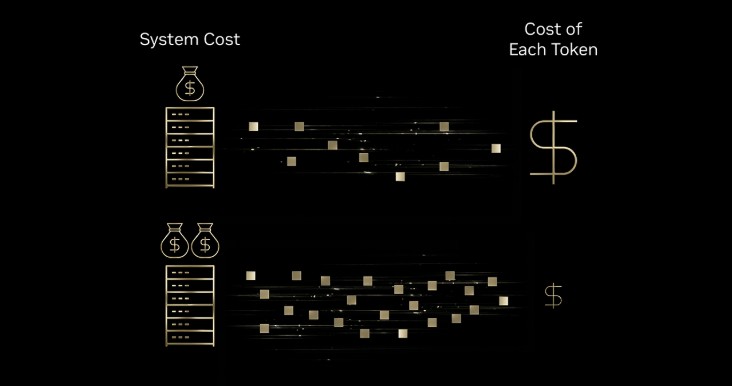
엔비디아가 블랙웰 플랫폼을 통해 주요 추론 서비스 제공업체들이 토큰당 비용을 최대 10배까지 낮추고 있다고 밝혔다. 오픈소스 모델과 블랙웰 기반 최적화 추론 스택을 결합해 의료·게이밍·고객 서비스 전반에서 비용 효율을 끌어올리고 있다. AI 기반 상호작용은 ‘토큰’ 단위로 작동한다. 기업이 더 많은 추론 요청을 처리하려면 동일 인프라에서 더 많은 토큰을 생성해야 한다. 엔비디아는 인프라와 알고리즘 효율 개선이 토큰 생산성을 높이고 결과적으로 토큰당 비용을 낮추는 핵심 요인이라고 설명했다.
추론 서비스 제공업체, 블랙웰 채택 확대
베이스텐, 딥인프라, 파이어웍스 AI, 투게더 AI는 블랙웰 기반 인프라로 전환하고 있다. 저정밀 NVFP4 형식과 TensorRT-LLM, 다이나모 추론 프레임워크를 결합해 처리량을 높이고 지연 시간을 줄였다. 엔비디아는 블랙웰이 호퍼 대비 달러당 처리량을 크게 개선해 토큰당 비용을 최대 10배까지 낮출 수 있다고 밝혔다.
의료: 설리.ai, 추론 비용 90% 절감
설리.ai는 의료 코드 작성과 진료 기록 자동화를 위해 베이스텐의 모델 API를 활용해 블랙웰 GPU에서 오픈소스 모델을 운영하고 있다. 기존 폐쇄형 모델 대비 추론 비용을 10배, 즉 90% 줄였고 의료 기록 생성 워크플로우의 응답 시간을 65% 개선했다. 이를 통해 의료진의 행정 업무 부담을 낮추고 3천만 분 이상의 시간을 환원했다고 설명했다.
게이밍: 래티튜드, 토큰당 비용 4배 절감
래티튜드는 AI 던전과 보야지 플랫폼에서 블랙웰 기반 딥인프라 추론 플랫폼을 활용한다. MoE 모델 운영 비용을 호퍼 기준 100만 토큰당 20센트에서 5센트 수준까지 낮추며 토큰당 비용을 총 4배 절감했다. 높은 정확도를 유지하면서도 실시간 응답을 제공하는 구조다.
에이전틱 챗·고객 서비스도 비용 구조 개선
센티언트는 블랙웰 기반 파이어웍스 AI 추론 플랫폼을 적용해 호퍼 대비 25~50% 수준의 비용 효율 개선을 달성했다. 대규모 동시 사용자 환경에서도 낮은 지연을 유지했다.
데카곤은 투게더 AI와 협력해 블랙웰 GPU 기반 멀티모델 음성 스택을 운영한다. 추측 디코딩과 캐싱, 자동 확장 최적화를 통해 질의당 비용을 기존 폐쇄형 모델 대비 6배 절감하고 400ms 이하 응답을 구현했다.

GB200 NVL72·루빈으로 확장
엔비디아는 GB200 NVL72 시스템이 추론용 MoE 모델에서 호퍼 대비 토큰당 비용을 최대 10배까지 낮출 수 있다고 밝혔다. 이어 루빈 플랫폼은 6개 신규 칩을 단일 AI 슈퍼컴퓨터로 통합해 블랙웰 대비 최대 10배 성능 향상과 10배 비용 절감을 제공한다고 설명했다.
#엔비디아 #블랙웰 #GB200NVL72 #루빈 #AI추론 #토큰당비용 #TensorRTLLM #토크노믹스









