- GB300 NVL72, 호퍼 대비 메가와트당 처리량 최대 50배 향상…저지연 환경 100만 토큰당 비용 35배 절감

엔비디아가 차세대 블랙웰 울트라 플랫폼을 공개하고 에이전틱 AI 추론 인프라 경쟁을 본격화했다. GB300 NVL72 시스템은 기존 호퍼 플랫폼 대비 메가와트당 처리량을 최대 50배 향상시키고, 저지연 환경에서 100만 토큰당 비용을 최대 35배 절감했다. 처리량과 토큰 비용을 동시에 낮추며 대규모 추론 환경의 총소유비용 구조를 크게 바꿨다.
에이전틱 AI 확산, 추론 인프라가 경쟁력 좌우
OpenRouter의 ‘State of Inference’ 보고서에 따르면 AI 에이전트와 코딩 어시스턴트 확산으로 소프트웨어 프로그래밍 관련 AI 쿼리는 지난해 11%에서 약 50% 수준으로 급증했다. 다단계 워크플로 전반에서 실시간 반응성을 유지하려면 저지연 처리와 긴 컨텍스트 대응 역량이 필수 요건으로 자리 잡고 있다.
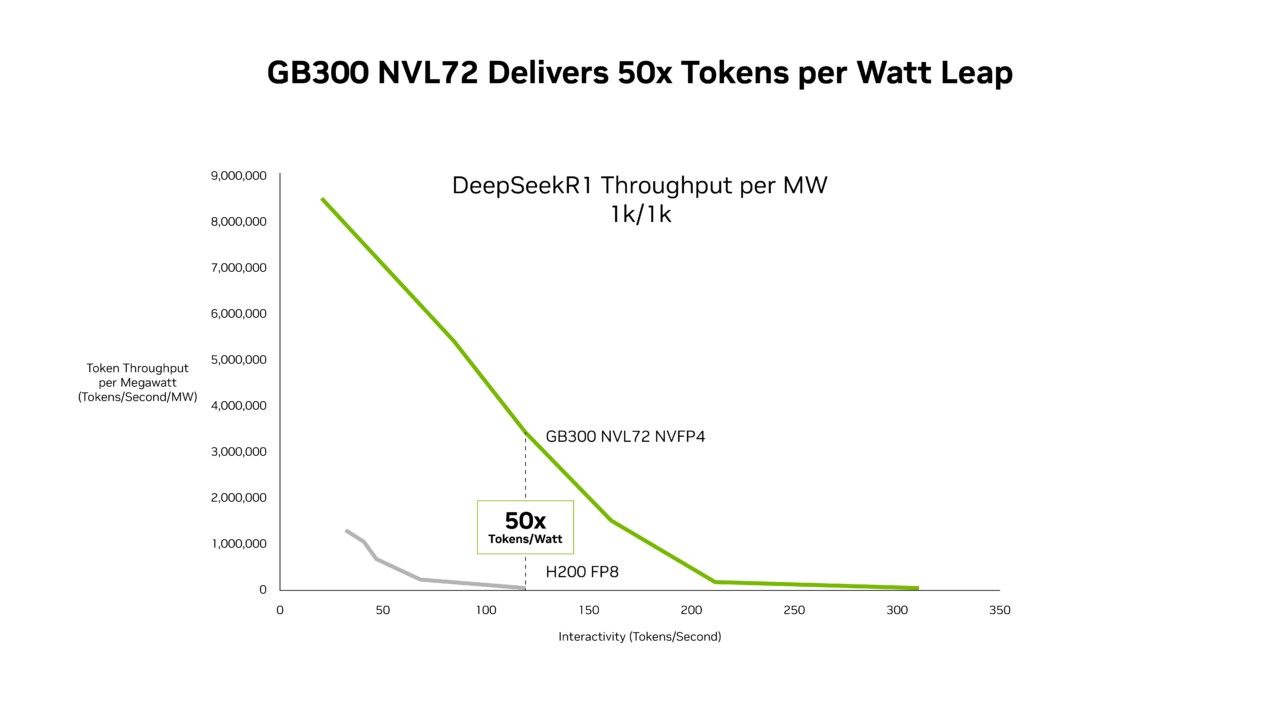
SemiAnalysis InferenceX 데이터는 블랙웰 울트라와 엔비디아 소프트웨어 최적화 기술의 결합이 성능과 비용을 동시에 개선했다고 분석했다. GB300 NVL72는 호퍼 대비 메가와트당 처리량을 최대 50배 향상시키고, 토큰당 비용을 최대 35배 절감했다. 총소유비용(TCO) 관점에서도 추론 워크로드의 경제성을 크게 높였다.
GB300 NVL72, 저지연 워크로드 성능 구조 개선
엔비디아 텐서RT-LLM, 다이나모, 문케이크, SGLang 등으로 구성된 공동 설계 소프트웨어 스택은 전문가 혼합(MoE) 추론 처리량을 전 구간에서 끌어올렸다. 최근 4개월 사이 저지연 워크로드 성능은 최대 5배 개선됐다.
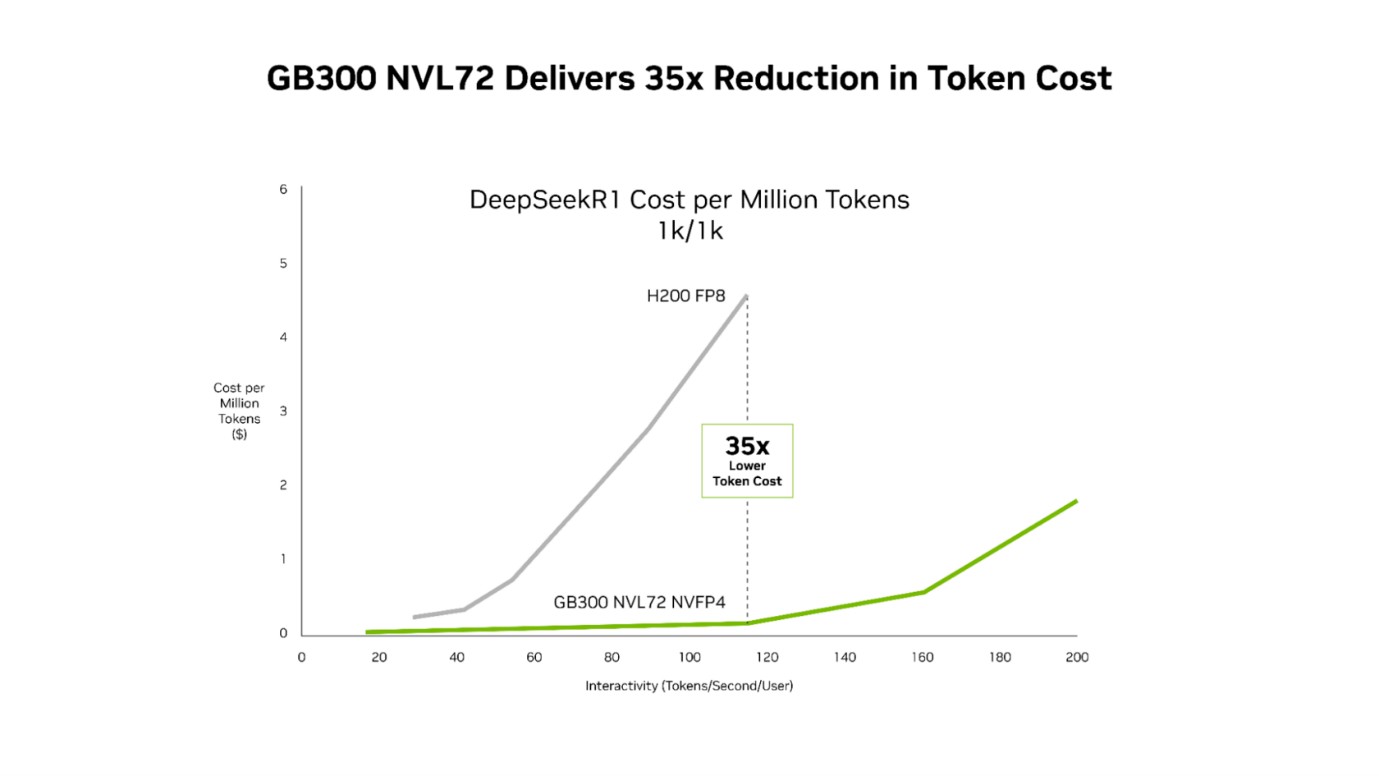
고성능 GPU 커널 최적화, NV링크 시메트릭 메모리, 프로그래매틱 디펜던트 런치 기술은 GPU 간 통신 효율을 높이고 유휴 시간을 줄였다. 칩과 시스템 아키텍처, 소프트웨어를 함께 설계하는 전략이 에너지 효율과 처리량을 동시에 끌어올렸다. 그 결과 GB300 NVL72는 지연 시간 전 구간에서 호퍼 대비 우수한 비용 구조를 구현했다.
긴 컨텍스트 환경에서 토큰 경제성 강화
GB300 NVL72는 128,000 토큰 입력과 8,000 토큰 출력을 처리하는 긴 컨텍스트 워크로드에서 강점을 보인다. GB200 NVL72 대비 토큰당 비용을 최대 1.5배 낮췄다. NVFP4 연산 성능은 1.5배 향상됐고 어텐션 처리 속도는 2배 빨라졌다. 대규모 코드베이스를 추론하는 에이전트 환경에서 처리 효율과 응답 속도를 동시에 확보할 수 있다.
클라우드 사업자, GB300 도입 확대
MS, 코어위브, OCI 등 주요 클라우드 사업자는 GB300 NVL72를 에이전틱 코딩과 긴 컨텍스트 활용 사례에 적용하고 있다. 토큰 비용을 낮추면서 대규모 코드베이스를 실시간으로 추론하는 환경을 구축하고 있다는 설명이다. 코어위브 첸 골드버그 엔지니어링 총괄 부사장은 “긴 컨텍스트 처리 성능과 토큰 효율성이 AI 프로덕션 환경의 핵심 요소로 자리 잡았으며, GB300 시스템은 대규모 워크로드에서도 예측 가능한 성능과 비용 구조를 제공한다”고 밝혔다.
차세대 루빈 플랫폼, 추가 도약 예고
엔비디아는 차세대 ‘루빈(Rubin)’ 플랫폼을 통해 또 한 번의 성능 도약을 예고했다. 루빈은 6개의 신규 칩을 통합해 AI 슈퍼컴퓨터를 구성하며, MoE 추론에서 블랙웰 대비 메가와트당 최대 10배 높은 처리량과 100만 토큰당 10분의 1 수준 비용을 목표로 한다.
블랙웰 울트라와 루빈 플랫폼은 에이전틱 AI 시대에 필요한 대규모 추론 인프라 경쟁을 본격화하는 핵심 축으로 자리 잡을 전망이다.
#엔비디아 #BlackwellUltra #GB300NVL72 #에이전틱AI #AI추론 #MoE #TensorRTLLM #루빈
 엔비디아, NVFP4로 저정밀 AI 훈련·추론 경쟁 본격화…MLPerf서 FP...
엔비디아, NVFP4로 저정밀 AI 훈련·추론 경쟁 본격화…MLPerf서 FP...
 델 프라이빗 클라우드, 뉴타닉스 AHV 지원…멀티 하이퍼바이저 분...
델 프라이빗 클라우드, 뉴타닉스 AHV 지원…멀티 하이퍼바이저 분...







