- 블랙웰 B200, 텐서RT LLM v1.0과 병렬화·추측 디코딩 기술로 처리량 3배 증가
- GB200 NVL72 5백만 달러 투자로 7천5백만 달러 수익… 15배 ROI 달성

엔비디아는 차세대 AI 플랫폼 블랙웰(NVIDIA Blackwell)이 새로 발표된 인퍼런스MAX(InferenceMAX) v1 벤치마크에서 최고 성능을 기록했다고 밝혔다. 이번 결과는 블랙웰이 AI 추론 분야에서 높은 처리량과 효율성, 비용 경쟁력을 동시에 갖췄음을 보여주며, 풀스택 하드웨어·소프트웨어 공동 설계를 기반으로 AI 데이터센터의 생산성과 투자수익률(ROI)을 크게 향상시켰음을 입증했다.
엔비디아 GB200 NVL72 시스템에 5백만 달러를 투자하면 7천5백만 달러의 토큰 수익을 창출할 수 있어 15배 ROI를 달성한다. 블랙웰 B200 시스템은 텐서RT LLM v1.0, 고급 병렬화 기술, 추측 디코딩 방식을 활용해 gpt-oss-120b 모델의 처리량을 3배 향상시키며 GPU당 6만 TPS를 기록했다. 라마 3.3 70B 등 밀집형 AI 모델에서도 인퍼런스MAX v1 벤치마크를 통해 새로운 성능 표준을 제시했다.
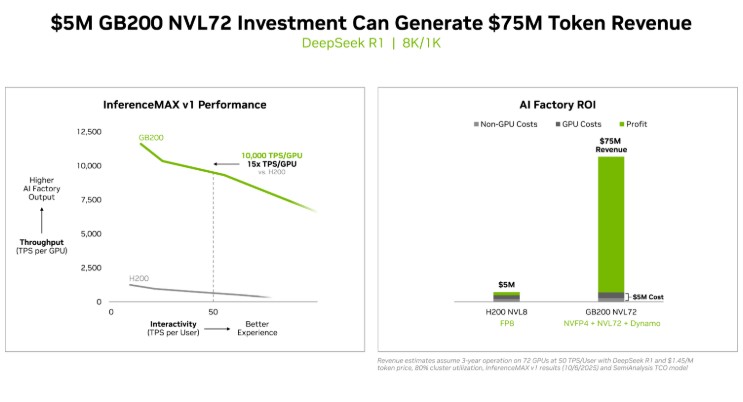
블랙웰은 GPU당 1만 TPS 이상, 사용자당 상호작용성 기준 50 TPS를 제공하며, 엔비디아 H200 대비 GPU 당 처리량이 4배 향상됐다. 와트당 토큰 수, 백만 토큰당 비용, 사용자당 TPS 등 효율성 지표에서도 탁월한 성과를 보이며, 전력이 제한된 AI 팩토리 환경에서도 토큰 수익과 처리량을 극대화한다.
엔비디아는 하드웨어와 소프트웨어 공동 설계, 텐서RT-LLM, 다이나모(Dynamo), SGLang, vLLM 등 오픈소스 추론 프레임워크, NV링크 스위치와 NVFP4 저정밀도 포맷 등 기술을 통해 지속적인 성능 향상을 실현했다. 또한, 오픈AI, 메타, 딥시크 AI 등과 협업해 최신 모델이 대규모 AI 인프라에서 최적 성능을 발휘하도록 지원한다.
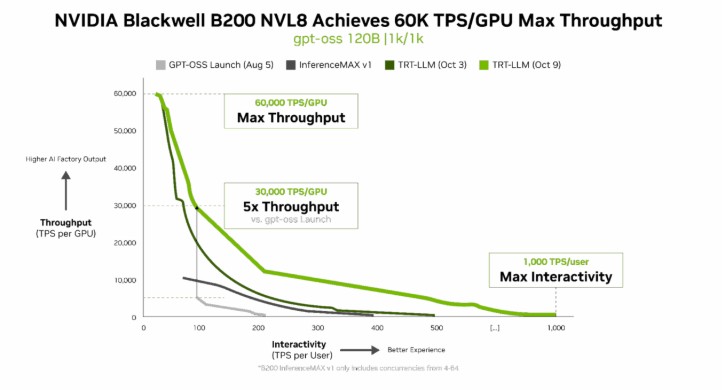
인퍼런스MAX v1 벤치마크는 데이터센터 처리량과 반응성, 비용, 에너지 효율성을 종합적으로 평가하며, 블랙웰의 풀스택 설계가 실제 AI 배포에서 최고의 ROI를 제공함을 입증했다. 엔비디아는 이러한 성과를 통해 AI 추론의 경제성과 성능, 확장성을 동시에 향상시키는 플랫폼 리더십을 강화하고 있다.
#엔비디아 #블랙웰 #InferenceMAX #AI추론 #텐서RT #B200 #GPU #AI데이터센터 #ROI #추측디코딩 #AI성능



















