- 1조 개 이상 파라미터 기반 강화학습으로 추론·지식 처리 성능 대폭 강화
- 적응형 도구 활용과 테스트 단계 확장으로 복합 추론·에이전트 역량 고도화
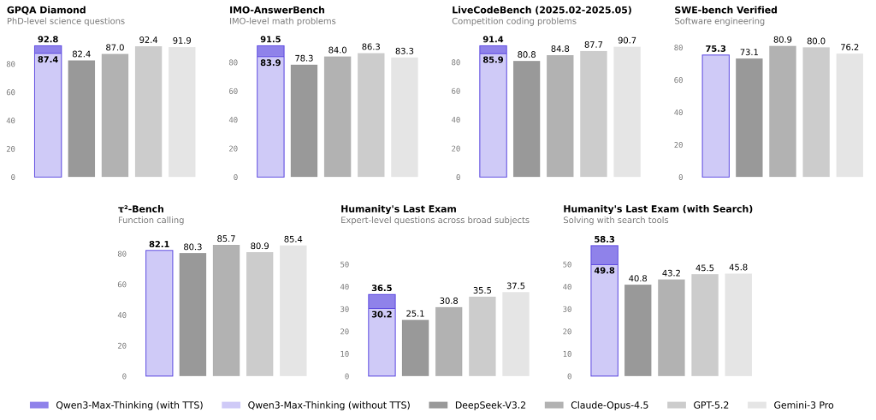
알리바바가 최신 추론 모델 ‘Qwen3-Max-Thinking’을 공개하며 초대규모 강화학습 기반 AI 경쟁력 강화에 나섰다. 알리바바에 따르면 Qwen3-Max-Thinking은 1조 개 이상의 파라미터로 모델 규모를 확장하고 강화학습을 적용해 사실적 지식 처리, 복합 추론, 지시 수행, 인간 선호도 정렬, 에이전트 기능 등 핵심 영역 전반에서 성능을 끌어올렸다.
19개 주요 벤치마크서 최신 초거대 모델과 경쟁력 입증
Qwen3-Max-Thinking은 총 19개 주요 벤치마크 평가에서 Claude Opus 4.5, Gemini 3 Pro, GPT-5.2-Thinking-xhigh 등 최신 고성능 추론 모델들과 비교해 경쟁력 있는 선도 성능을 기록했다. 과학·수학·코딩 문제 해결은 물론, 검색 도구를 활용해 다양한 분야의 전문가급 질문을 해결하는 평가 항목에서도 높은 정확도와 일관성을 보이며 범용 추론 모델로서의 완성도를 입증했다.
적응형 도구 활용으로 검색·코드 실행을 자동 판단
Qwen3-Max-Thinking의 핵심 차별점 중 하나는 적응형 도구 활용(Adaptive Tool-use) 기능이다. 모델은 대화 맥락에 따라 검색(Search), 메모리(Memory), 코드 인터프리터(Code Interpreter)를 자동으로 선택·활용한다. 기존처럼 사용자가 직접 도구를 지정할 필요 없이, 모델이 문제 해결에 필요한 수단을 스스로 판단해 호출함으로써 복잡한 추론 과정을 보다 효율적으로 수행한다. 이 기능은 초기 미세 조정 이후, 규칙 기반과 모델 기반 피드백을 결합한 다중 과제 학습을 통해 구현됐다. 검색과 메모리 기능은 환각을 줄이고 실시간 정보 접근성을 높이며, 코드 인터프리터는 계산이나 실행 기반 추론이 필요한 복합 문제 해결을 지원한다.
경험 누적형 테스트 단계 확장으로 추론 효율 개선
알리바바는 고도화된 테스트 단계 확장(Test-time Scaling) 기법도 적용했다. 특히 경험 누적형 다회차 테스트 단계 확장 전략을 도입해, 이전 상호작용에서 도출된 핵심 정보를 정제·활용하도록 설계했다. 이를 통해 이미 확인된 결론을 반복적으로 재추론하지 않고, 남아 있는 불확실성 해결에 집중할 수 있도록 했다. 그 결과 동일하거나 유사한 토큰 비용 환경에서도 병렬 샘플링 및 집계 방식 대비 지속적으로 높은 추론 성능과 문맥 효율을 기록했다.
Qwen Chat·모델 스튜디오 통해 제공
Qwen3-Max-Thinking은 현재 Qwen Chat을 통해 이용할 수 있으며, 모델 API는 알리바바의 생성형 AI 개발 플랫폼 ‘모델 스튜디오(Model Studio)’에서 제공된다. 알리바바는 이번 모델 공개를 통해 초대규모 파라미터 기반 추론 모델 경쟁에서 기술적 존재감을 강화하고, 에이전트형 AI와 복합 문제 해결 중심의 차세대 활용 시나리오를 본격 확대한다는 전략이다.
#알리바바 #Qwen3MaxThinking #추론모델 #강화학습 #생성형AI #에이전트AI #초거대AI



















