알리바바 클라우드가 자사 큐원(Qwen) 시리즈의 통합 엔드투엔드 멀티모달 모델인 ‘Qwen2.5-Omni-7B’를 새롭게 공개했다.
이번 모델은 종합적인 멀티모달 인식을 위해 설계되어, 텍스트, 이미지, 음성, 영상 등 다양한 형태의 입력 정보를 처리하고 실시간 텍스트 및 자연스러운 음성 응답을 지원함으로써 모바일 기기와 노트북과 같은 엣지 디바이스에 최적화된 멀티모달 AI 기술의 새로운 표준을 제시한다.
Qwen2.5-Omni-7B는 7B(70억) 파라미터의 컴팩트한 설계에도 불구하고 성능 저하 없이 강력한 멀티모달 처리 능력을 제공한다. 이러한 고유한 조합은 특히 지능형 음성 애플리케이션과 같이 실질적인 가치를 제공하는 민첩하고 비용 효율적인 AI 에이전트 개발에 적합하다. 예를 들어 이 모델은 시각 장애인이 실시간 음성 설명을 통해 주변 환경을 인식하고 탐색할 수 있도록 지원하거나, 동영상 속 재료를 분석해 단계별 요리 가이드를 제공하는 데 활용될 수 있다. 또한 고객의 니즈를 정확히 이해하는 지능형 고객 응대 시스템 구현에도 적용 가능하다.
Qwen2.5-Omni-7B는 현재 허깅페이스(Hugging Face)와 깃허브(GitHub)를 통해 오픈소스로 공개되었으며, 큐원 챗(Qwen Chat)과 알리바바 클라우드 오픈소스 커뮤니티인 모델스코프(ModelScope)를 통해서도 접근할 수 있다. 알리바바 클라우드는 지난 몇 년간 총 200개 이상의 생성형 AI 모델을 오픈소스로 공개한 바 있다.
혁신적 아키텍처 기반의 고성능 멀티모달 처리
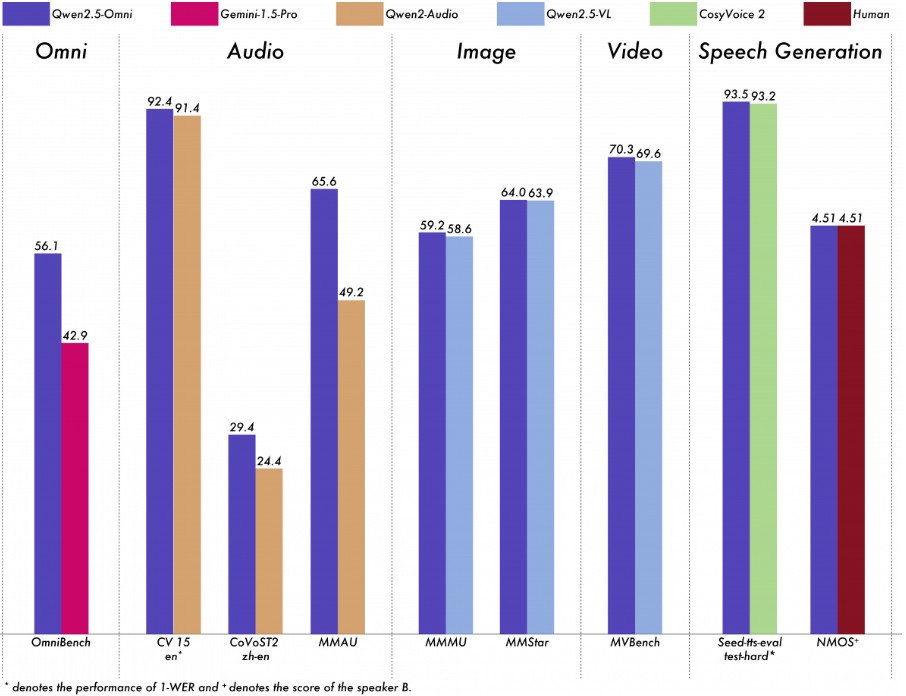
Qwen2.5-Omni-7B는 모든 모달리티 중에서 뛰어난 성능을 발휘하며, 유사한 규모의 단일 모달리티 특화 모델과 비교해도 손색이 없다. 특히 실시간 음성 상호작용, 자연스럽고 안정적인 음성 생성, 엔드투엔드 음성 명령어 이행 등에서 업계 최고 수준의 벤치마크를 제시했다.
해당 모델의 효율성과 고성능은 혁신적인 아키텍처에서 비롯된다. 대표적으로 텍스트 생성(Thinker)과 음성 합성(Talker)을 분리하여 서로 다른 모달 간의 간섭을 최소화하는 ‘Thinker-Talker 아키텍처’, 일관된 콘텐츠 생성을 위해 비디오 입력과 오디오를 보다 잘 동기화하는 위치 임베딩 기술 TMRoPE(Time-aligned Multimodal RoPE), 그리고 끊김 없는 음성 상호작용을 위한 저지연 오디오 응답을 가능하게 하는 블록와이즈 스트리밍 처리 등이 적용되었다.