





- 에이전틱 코딩·멀티모달 추론·음성·영상 통합 처리 기반 AI 실행 범위 확대
알리바바(Alibaba)가 에이전틱 실행 기반 코딩 모델 Qwen3.6-Plus와 텍스트·음성·이미지·영상 데이터를 통합 처리하는 옴니모달 모델 Qwen3.5-Omni를 공개했다. 복합 작업을 단계적으로 수행하는 실행 구조와 멀티모달 처리 범위를 확장해 소프트웨어 개발 자동화와 실시간 상호작용형 AI 적용 영역을 동시에 넓혔다.
에이전틱 실행 구조와 옴니모달 모델 병행 공개
두 모델은 서로 다른 활용 목적에 맞춰 개발됐다. Qwen3.6-Plus는 코드 생성 이후 테스트와 반복 개선 과정을 이어가는 에이전틱 실행 흐름에 초점을 맞췄으며 Qwen3.5-Omni는 텍스트·음성·이미지·영상 입력을 단일 모델에서 함께 처리하는 옴니모달 구조를 사용한다. 인식·추론·행동 단계를 하나의 흐름으로 연결해 다단계 작업을 연속적으로 수행한다.
Qwen3.6-Plus, 저장소 단위 엔지니어링 작업 자동화
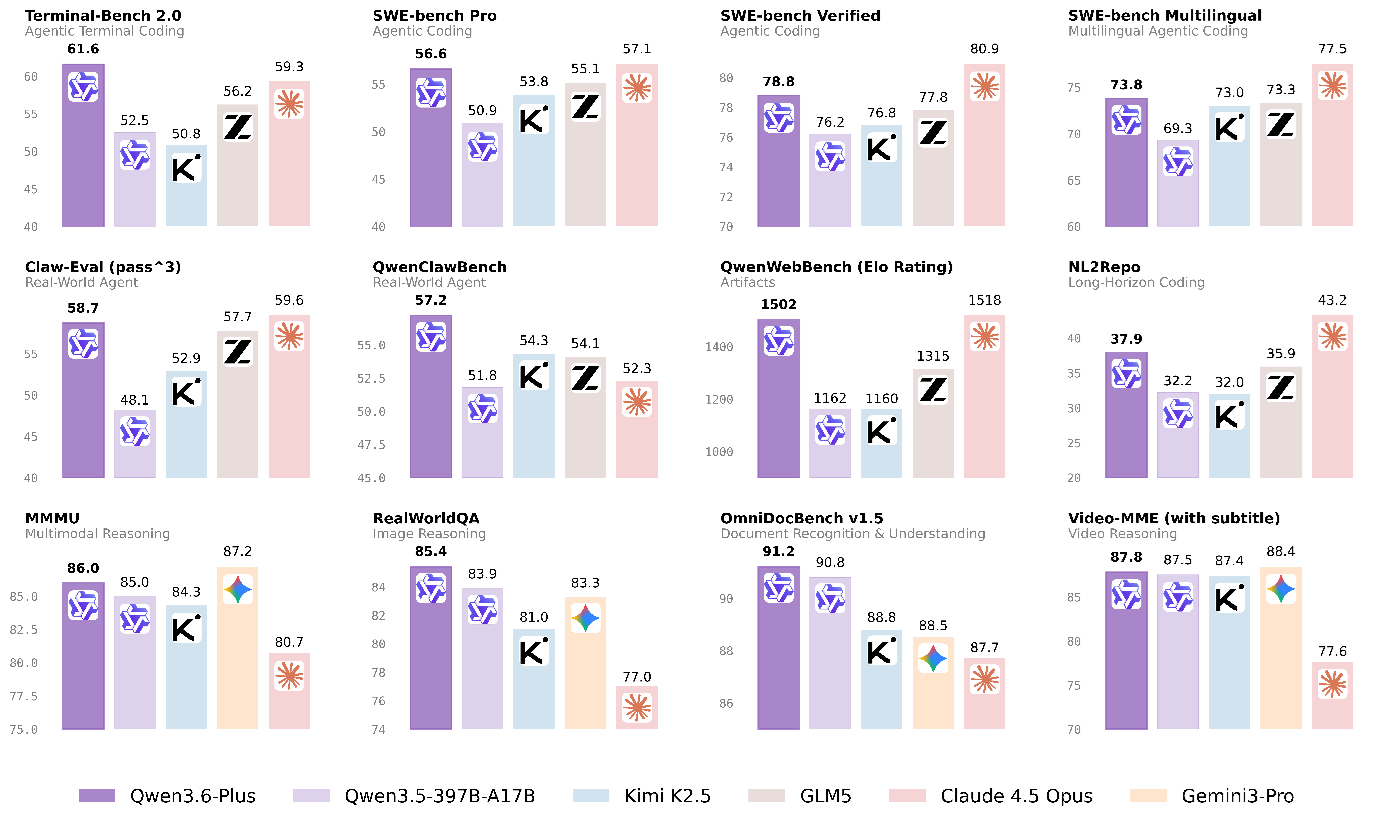
Qwen3.6-Plus는 저장소(repository) 단위 코드 분석과 실제 시각 환경 기반 문제 해결을 수행하는 에이전틱 실행 모델이다. 능력 루프(Capability Loop)는 인식·추론·행동 단계를 하나의 워크플로로 연결해 코드 생성 이후 테스트와 반복 개선 과정을 이어가며 최대 100만 토큰 컨텍스트를 지원해 장문 문서와 대규모 코드베이스를 함께 분석한다.
멀티모달 추론 기능은 고밀도 문서 파싱, 실제 환경 이미지 해석, 장편 영상 이해 작업을 포함한다. UI 스크린샷, 손그림 와이어프레임, 제품 프로토타입을 입력 데이터로 활용해 프론트엔드 코드 생성까지 이어지는 시각적 코딩 기능을 제공한다.
Model Studio와 Qwen Chat에서 사용할 수 있으며 OpenClaw, Claude Code, Cline 등 외부 개발 도구와 연동된다. 일부 모델은 개발자 친화적 규모의 오픈소스 형태로 공개될 예정이다.
Qwen3.5-Omni, 텍스트·음성·영상 통합 처리 모델
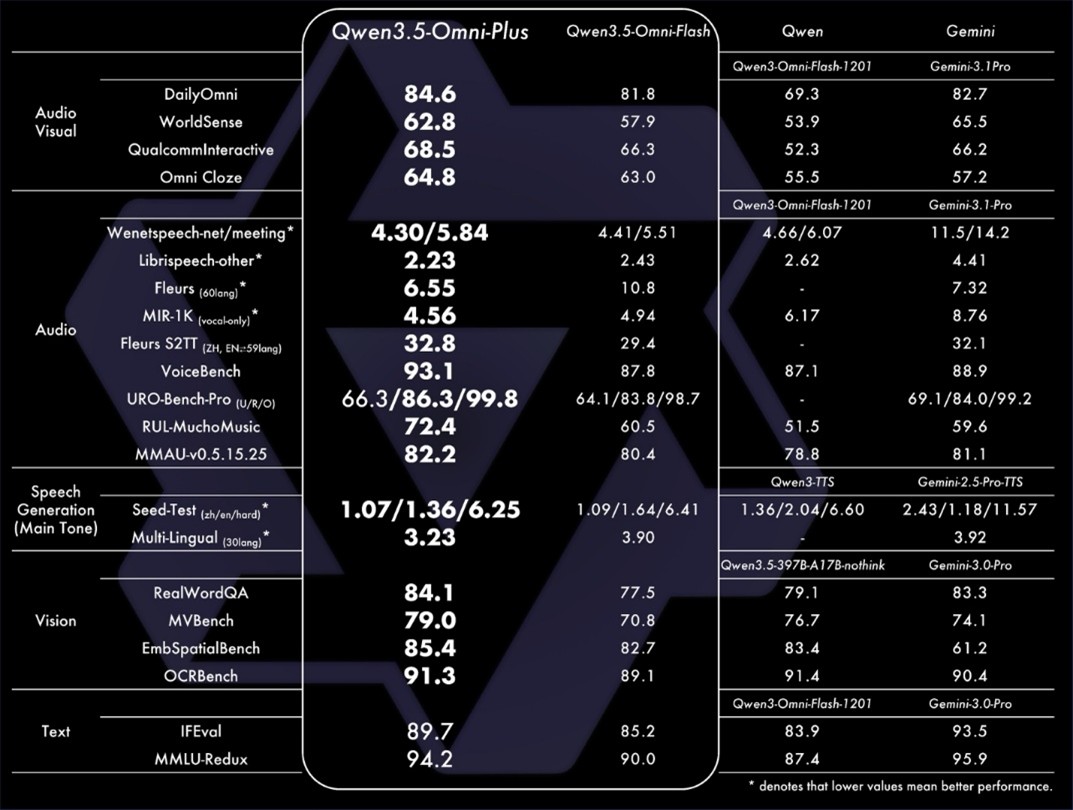
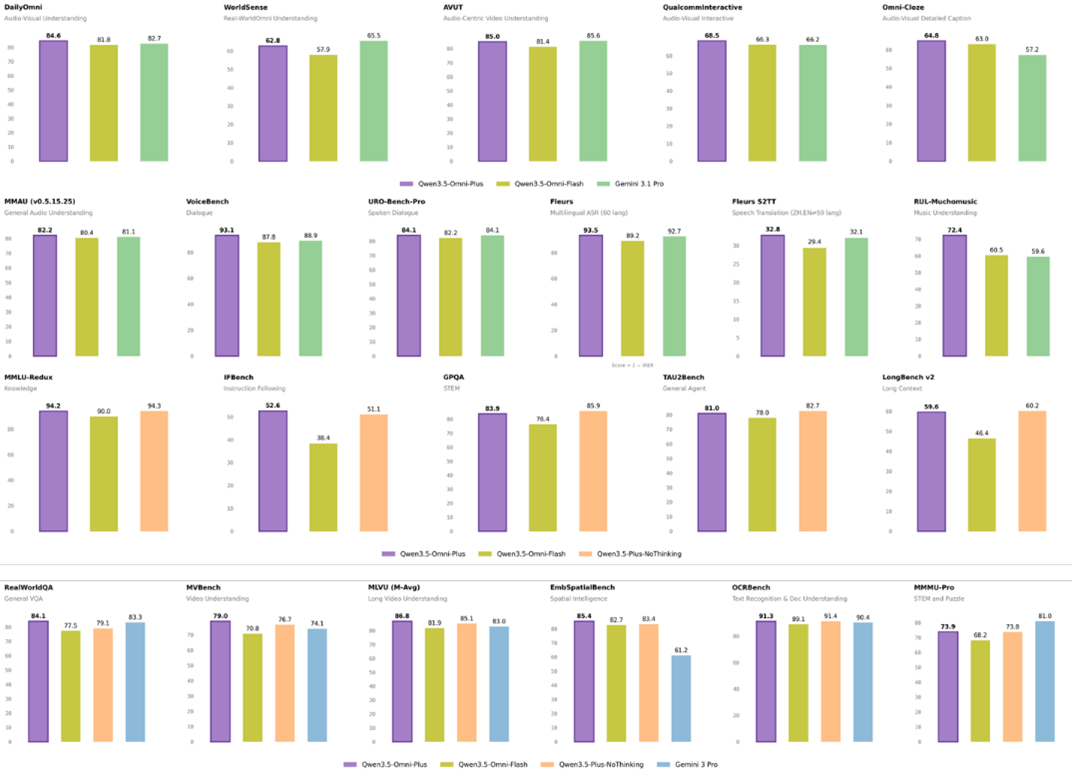
Qwen3.5-Omni는 텍스트, 음성, 이미지, 영상 데이터를 하나의 모델에서 함께 처리하는 옴니모달 AI 모델이다. 텍스트와 음성을 출력 형태로 제공하며 실시간 상호작용과 오프라인 분석 작업을 하나의 실행 흐름에서 수행한다. 라이브 스트리밍, 음성 비서, 영상 자막 생성과 같은 멀티모달 기반 서비스에 활용된다.
Plus·Flash·Light 세 가지 버전으로 제공되며 최대 256K 토큰 컨텍스트를 지원한다. Qwen3.5-Omni-Plus는 200개 이상의 벤치마크에서 상위 수준 결과를 기록했으며 음성 이해, 추론, 음성 인식, 다국어 번역 영역에서 성능 평가 범위를 넓혔다.
Hybrid-Attention Mixture-of-Experts 아키텍처를 기반으로 10시간 이상의 연속 오디오 입력을 처리하며 1억 시간 이상의 음성·영상 데이터를 포함한 학습 데이터를 활용했다. 음성 인식은 113개 언어와 방언, 음성 생성은 36개 언어를 지원한다.
장면 단위 분할과 타임스탬프 정렬을 통해 등장인물 관계와 맥락 정보를 포함한 구조화된 설명을 생성한다. Audio-Visual Vibe Coding 기능은 음성 설명과 스케치를 입력 데이터로 활용해 앱·웹 인터페이스 프로토타입 생성 흐름을 제공한다. ARIA(Adaptive Rate Interleave Alignment) 기술을 적용해 스트리밍 환경에서 음성 합성 안정성을 높였다.
#알리바바 #Qwen #Qwen36Plus #Qwen35Omni #에이전틱AI #옴니모달AI #멀티모달 #MixtureofExperts #AI코딩 #AudioVisualAI
 한국레노버, 산업용 AI 엣지 컴퓨팅 ‘씽크엣지’ 2종 출시…온디바...
한국레노버, 산업용 AI 엣지 컴퓨팅 ‘씽크엣지’ 2종 출시…온디바...









