





- 대규모 언어 모델(LLM) 훈련 속도 최대 30% 향상
- 엔비디아 AI 플랫폼 네모 메가트론, A100 GPU 사용한 컨테이너형 프레임워크
- LLM, 실시간 콘텐츠 생성과 고객 서비스 챗봇 등 대화형 AI 인터페이스 발전 제공
엔비디아가 대규모 언어 모델(LLM)의 크기와 복잡성이 지속적으로 급증함에 따라 최대 30%의 훈련 속도 향상을 제공하는 네모 메가트론(NeMo Megatron) 프레임워크의 업데이트를 발표했다. 이번 업데이트는 두 가지 선구적인 기술과 여러 GPU에서 LLM 훈련을 최적화하고 확장하는 하이퍼 파라미터(hyper parameter) 도구를 포함한다. 이를 통해 엔비디아 AI 플랫폼으로 모델을 훈련하고 구축할 수 있는 새로운 기능을 제공한다.
1,760억 개의 파라미터(parameter)를 가진 세계 최대 오픈 사이언스, 오픈 액세스 다국어 언어 모델인 블룸(BLOOM)은 최근 엔비디아 AI 플랫폼에서 훈련돼 46개 언어와 13개 프로그래밍 언어로 텍스트 생성을 가능하게 했다. 또한 엔비디아 AI 플랫폼은 5,300억 개의 파라미터를 포함하는 가장 강력한 변환기 언어 모델인 메가트론-튜링 NLG 모델(MT-NLG)을 지원한다.
LLM의 최신 발전
LLM은 텍스트에서 학습하는 최대 수조 개의 파라미터를 포함하는 오늘날 가장 중요한 첨단 기술 중 하나다. 하지만 이를 개발하려면 심층적인 기술 전문 지식, 분산된 인프라, 전체 스택 접근 방식이 필요해 비용과 시간이 많이 든다. 그러나 실시간 콘텐츠 생성, 텍스트 요약, 고객 서비스 챗봇, 대화형 AI 인터페이스를 위한 질문과 답변을 발전시키는 데 있어 큰 이점을 갖는다.
AI 커뮤니티는 LLM을 발전시키기 위해 메가트론(Megatron)-LM, 에이펙스(Apex), 그리고 기타 GPU 가속 라이브러리를 포함하는 엔비디아 AI 플랫폼을 기반으로 하는 마이크로소프트 딥스피드(Microsoft DeepSpeed), Colossal-AI, 허깅 페이스 빅사이언스(Hugging Face BigScience), 페어스케일(Fairscale) 같은 도구의 혁신을 이어가고 있다.
엔비디아는 오늘날 엔비디아 AI 플랫폼에 대한 새로운 최적화를 통해 스택 전체에서 기존의 많은 문제점을 해결하며, AI 커뮤니티와 협력해 모든 사람이 LLM의 기능에 액세스할 수 있기를 기대하고 있다.
LLM 구축 시간 단축
네모 메가트론의 최신 업데이트는 220억에서 1조 파라미터에 이르는 크기의 GPT-3 모델 훈련 속도를 30% 향상시킨다. 이는 1,024개의 엔비디아 A100 GPU를 사용해 1,750억 개의 파라미터 모델에 대한 훈련을 24일 만에 수행하도록 한다. 즉, 결과 도출 시간을 10일 또는 GPU 컴퓨팅 시간으로 약 250,000 시간 단축할 수 있다.
네모 메가트론은 빠르고 효율적이며 사용하기 쉬운 엔드 투 엔드 컨테이너형 프레임워크이다. 데이터 수집, 대규모 모델 훈련, 업계 표준 벤치마크에 대한 모델 평가, 지연 시간과 처리량 성능에 대한 최첨단 추론이 가능하다.
이를 통해 LLM 훈련과 추론을 다양한 GPU 클러스터 구성에서 쉽게 재현할 수 있다. 현재 얼리 액세스 고객에게 엔비디아 DGX 슈퍼POD(SuperPOD), 엔비디아 DGX 파운드리(Foundry), 마이크로소프트 애저(Microsoft Azure) 클라우드 플랫폼을 제공한다. 또한 다른 클라우드 플랫폼에 대한 지원도 제공될 예정이다.
더불어 사용자에게 엔비디아 가속 인프라의 실습 랩 카탈로그에 대한 단기 액세스를 제공하는 무료 프로그램인 엔비디아 런치패드(LaunchPad)에서 기능을 체험할 수 있다.
LLM 훈련 속도를 높이는 두 가지 새로운 기술
LLM 훈련을 최적화하고 확장하는 업데이트에 포함된 두 가지 새로운 기술은 시퀀스 병렬화(SP)와 선택적 활성화 재계산(SAR)이다.
시퀀스 병렬화(SP)는 이전에 병렬화 되지 않은 변환기 레이어의 영역이 시퀀스 차원을 따라 독립적이라는 점을 인식해 텐서 수준 모델 병렬화를 확장한다.
시퀀스 차원을 따라 이러한 레이어를 분할함으로써 텐서 병렬 장치 전반에 걸쳐 컴퓨팅 및 가장 중요한 활성화 메모리를 분산할 수 있다. 활성화가 분산되므로 재계산 대신 역방향 패스에 대해 더 많은 활성화를 저장할 수 있다.
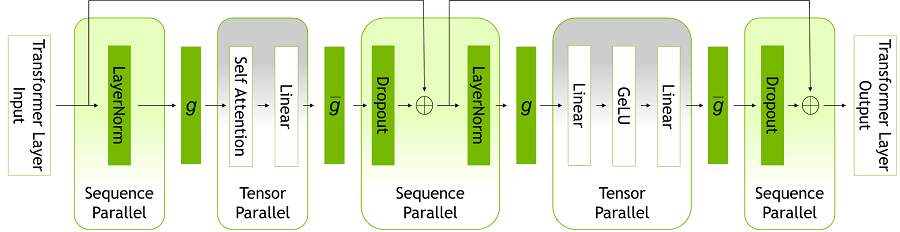
[그림 1] 변환기 레이어 내의 병렬화 모드
[시퀀스 병렬화는 레이어놈(LayerNorm)과 드롭아웃(Dropout) 레이어에서 사용되는 반면 텐서 병렬화는 어텐션 및 FFN 레이어에서 사용된다]
선택적 활성화 재계산은 다른 활성화가 재계산하는 데 다른 수의 작업이 필요하다는 점을 인식한다. 이를 통해 메모리 제약으로 인해 활성화의 전부가 아닌 일부를 재계산해야 하는 경우를 개선한다.
전체 변환기 레이어를 검사하고 재계산하는 대신, 상당한 양의 메모리를 차지하지만 재계산하는 데 계산 비용이 많이 들지 않는 각 변환기 레이어의 부분만 검사하고 재계산할 수 있다.
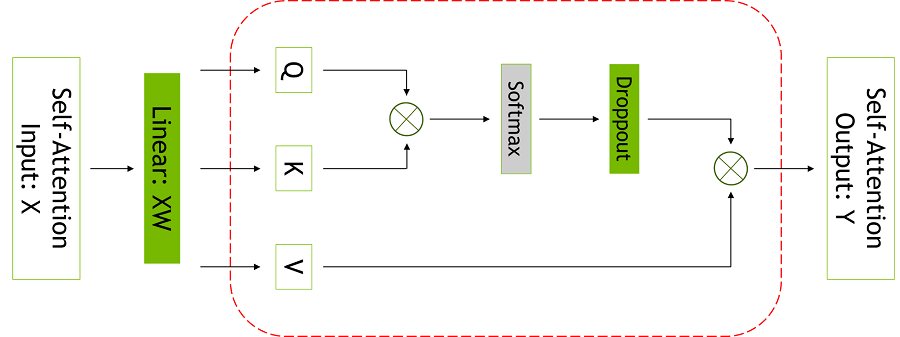
[그림 2] 셀프 어텐션 블록. 빨간색 점선은 선택적 활성화 재계산이 적용되는 영역을 나타낸다.
[어텐션 레이어 내에서 QKT 행렬 곱셈, 소프트맥스(softmax), 소프트맥스 드롭아웃, V 연산에 대한 어텐션 활성화가 재계산된다]
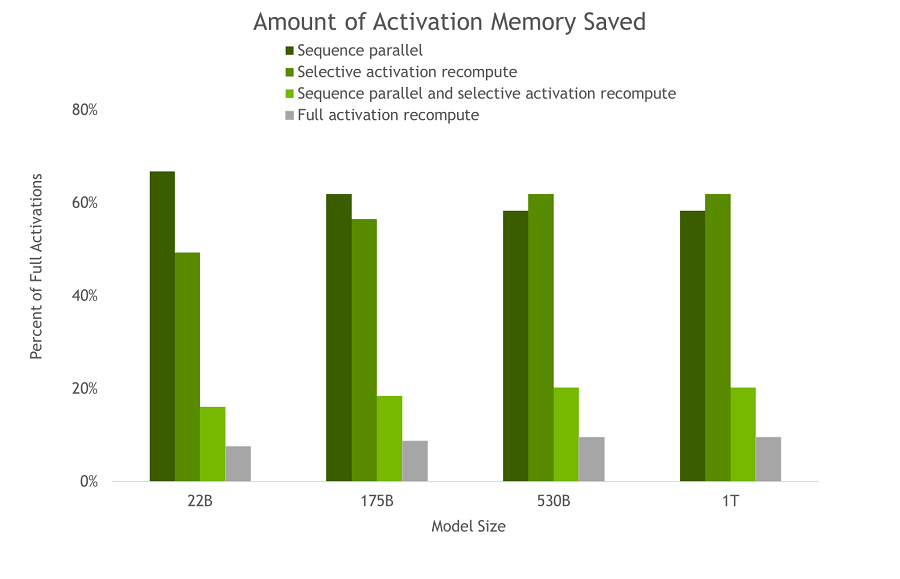
[그림 3] SP 및 SAR 덕분에 역방향 패스에 저장된 활성화 메모리의 양. 모델 크기가 증가함에 따라 SP와 SAR 모두 유사한 메모리 절약 효과를 나타내므로 필요한 메모리가 최대 5배 감소한다.
[시퀀스 병렬화 및 SAR은 메모리를 최대 5배 감소시킨다]
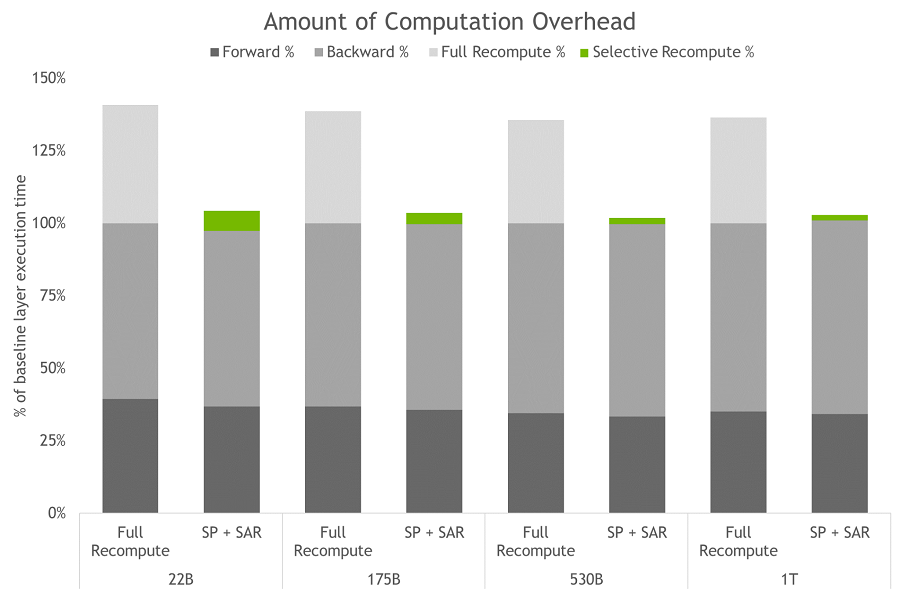
[그림 4] 전체 활성화 재계산 및 SP+SAR에 대한 계산 오버헤드 양.
막대는 순방향, 역방향 및 재계산 시간의 레이어별 분석을 나타낸다.
기준선은 재계산과 시퀀스 병렬화가 없는 경우이다. 이러한 기술은 모든 활성화가 저장되는 대신 재계산될 때 발생하는 오버헤드를 줄이는 데 효과적이다. 가장 큰 모델의 경우 오버헤드가 36%에서 2%로 떨어진다. 시퀀스 병렬화와 SAR은 함께 사용하면 오버헤드가 기준선의 2%로 감소한다.
LLM의 기능에 액세스하려면 고도로 최적화된 추론 전략도 필요하다. 사용자는 추론을 위해 훈련된 모델을 쉽게 사용하고 P-튜닝과 신속한 튜닝 기능을 사용하여 다양한 사용 사례에 최적화할 수 있다.
이러한 기능은 미세 조정에 대한 파라미터 효율적인 대안이며 LLM이 전체 사전 훈련된 모델을 미세 조정하는 강력한 접근 방식 없이 새로운 사용 사례에 적응할 수 있도록 한다. 이 기술에서는 원래 모델의 파라미터가 변경되지 않는다. 따라서 미세 조정 모델과 관련된 치명적인 '망각(forgetting)' 문제가 방지된다.
훈련과 추론을 위한 새로운 하이퍼 파라미터 도구
분산된 인프라에서 LLM 모델 구성을 찾는 과정에는 시간이 많이 소요된다. 네모 메가트론은 코드 변경 없이 최적의 훈련과 추론 구성을 자동으로 찾는 하이퍼 파라미터 도구를 도입한다. LLM은 처음부터 추론을 위해 수렴하도록 훈련되어 효율적인 모델 구성을 검색하는 데 시간을 낭비하지 않는다.
데이터 병렬화, 텐서 병렬화, 파이프라인 병렬화, 시퀀스 병렬화, 마이크로 배치 크기, 활성화 체크포인트 레이어 수(선택적 활성화 재계산 포함)와 같은 고유한 파라미터에 대한 경험적 그리드 검색을 사용하여 처리량이 가장 우수한 구성을 찾는다.
NGC의 컨테이너에 대한 엔비디아 테스트의 하이퍼 파라미터 도구를 사용하면 24시간 이내에 175B GPT-3 모델에 대한 최적의 훈련 구성에 도달한다(그림 5). 전체 활성화 재계산을 사용하는 일반적인 구성과 비교할 때 처리 속도가 20-30% 향상됐다. 더불어 최신 기술을 사용해 파라미터가 20B 이상인 모델의 처리 속도를 추가로 10-20% 향상시킨다.
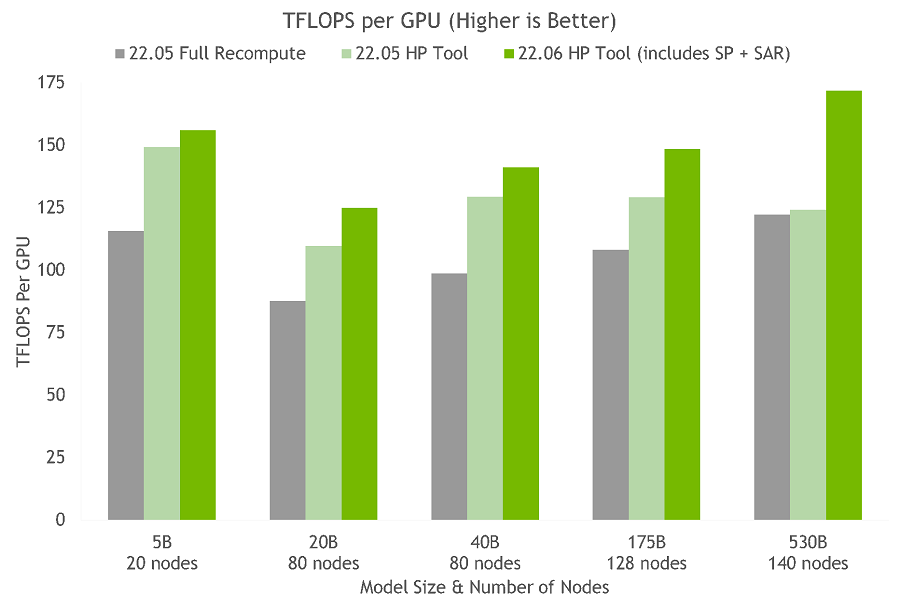
[그림 5] 각 노드가 엔비디아 DGX A100인 경우 시퀀스 병렬화 및 선택적 활성화 재계산을 통해
속도 향상을 나타내는 여러 컨테이너에 대한 HP 도구의 결과.
[시퀀스 병렬화와 선택적 활성화 재계산 기능이 있는 22.06 컨테이너는 전체 재계산 또는 HP도구 기능이 있는 22.05 컨테이너에 비해 30% 더 빠른 속도를 제공한다.]
하이퍼 파라미터 도구를 사용하면 추론 중에 처리량이 가장 높거나 지연 시간이 가장 짧은 모델 구성을 찾을 수 있다. 또한 지연 시간과 처리량 제약 조건을 제공해 모델을 지원할 수 있으며, 도구는 적합한 구성을 권장한다.
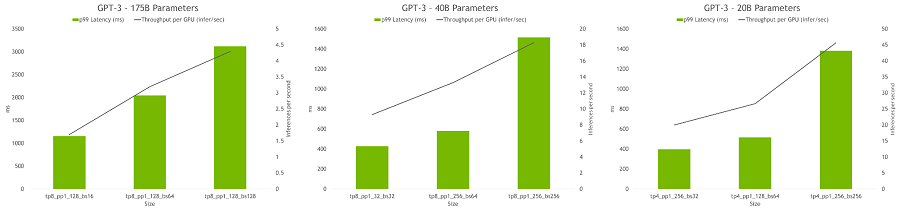
[그림 6] 추론을 위한 HP 도구 결과는 GPU당 처리량과 다양한 구성의 지연 시간을 보여준다. 최적의 구성에는 높은 처리량과 짧은 지연 시간이 포함된다.
[HP 도구는 추론을 위한 높은 처리량과 짧은 대기 시간을 제공하는 최적의 모델 구성을 찾는다. GPT-3: 175B, 40B, 20B 파라미터 모델에 대한 다양한 처리량과 대기시간 트레이드오프가 있는 여러 여러 구성이 그래프에 표시된다.]
#엔비디아#네모#메가트론#프레임워크#LLM










